Bloomberg Technoz, Jakarta - Optimalisasi teknologi pada Galaxy AI milik Samsung, termasuk dalam kemampuan mengembangkan fitur multi-bahasa, melibatkan para software developer asal Indonesia. SDM lokal akan mengeksplorasi mobile AI Samsung yang tergabung dalam tim Samsung Research di Indonesia (SRIN).
Peningkatan kemampuan berbahasa dari Galaxy AI on–device translation diantaranya Live Translate, Interpreter, Note Assist, dan Browsing Assist. Junaidillah Fadlil, Head of AI di SRIN, mengatakan bahwa kecerdasan buatan bertumpu awal pada data yang berkualitas dan relevan. SRIN baru-baru ini telah menambahkan dukungan Bahasa Indonesia di Galaxy AI
“Jadi, kami menggali lebih dalam untuk memahami kebutuhan linguistik dan keunikan dari Bahasa Indonesia. Pengembangan bahasa lokal harus didasarkan pada pemahaman dan ilmu pengetahuan, sehingga penambahan bahasa ke Galaxy AI dimulai dengan merencanakan informasi yang dibutuhkan oleh tim kami secara legal dan etis,” jelas Fadlil dalam keterangan resmi, dilansir Senin (13/5/2024).
Pengembangan fitur di Galaxy AI diketahui memerlukan data/informasi unik dengan melalui tiga tahapan inti; automatic speech recognition (ASR), neural machine translation (NMT), dan text-to-speech (TTS).
Lebih lanjut ASR membutuhkan rekaman suara di berbagai situasi dan kondisi, juga dilengkapi dengan transkripsi teks akurat. “Tingkat kebisingan rekaman suara yang bervariasi membantu mengakomodasi kondisi lingkungan yang berbeda.”
Informasi berbasis suara tidak hanya didapat dari pihak ketiga, namun tim ASR di SRIN mengumpulkan dari berbagai lingkungan (tempat kerja, kafe) untuk direkam.
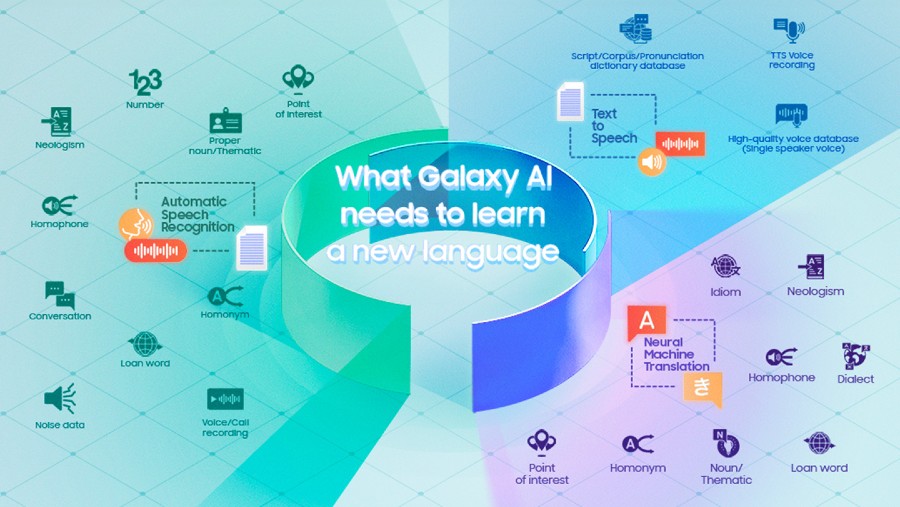
Hal ini memungkinkan kami untuk bisa menangkap suara-suara autentik yang unik dari kehidupan sehari-hari, seperti orang yang sedang memanggil atau ketikan keyboard, disampaikan Muchlisin Adi Saputra, Lead ASR.
“Kita perlu terus memperbarui bahasa slang terbaru dan cara penggunaannya. Kami banyak temukan dari media sosial,” terang dia.
Baca Juga: Fitur AI Jadi Unggulan Perangkat Samsung Galaxy S24
Tim NMT kemudian membutuhkan data untuk melatih terjemahan. “Penggunaan makna kontekstual dan implisit yang luas bergantung pada petunjuk sosial dan situasional. Data yang digunakan harus berisi banyak teks terjemahan sebagai referensi bagi AI untuk memahami kata-kata baru, kata-kata asing, kata benda, dan angka. Semua informasi dibutuhkan untuk membantu AI memahami konteks dan aturan komunikasi.” kata Muhammad Faisal, Lead NMT.

Untuk TTS memerlukan rekaman yang melibatkan berbagai macam suara dan nada, dengan pola kata terdengar dalam situasi yang berbeda. Harits Abdurrohman, Lead TTS, menegaskan.
“Rekaman suara yang baik mempercepat pekerjaan yang dilakukan karena mencakup satuan bunyi terkecil yang diperlukan AI untuk membedakan makna. Setelah mendapat rekaman suara yang baik pada fase awal, kami dapat fokus pada tahap selanjutnya yaitu penyempurnaan model AI agar dapat mengucapkan setiap kata dengan jelas,” pungkas dia.
(wep)